


Before organising a course or seminar, we listen to the real needs and objectives of each client, in order to adapt the training and get the most out of it. We tailor each course to your needs.
We are also specialists in 'in company' trainings adapted to the needs of each organisation, where the benefit for several attendees from the same company is much greater. If this is your case, contact us.
Ponemos a disposición también plataforma Cloud con todas las herramientas instaladas y configuradas, listas para la formación, incluyendo ejercicios, bases de datos, etc... para no perder tiempo en la preparación y configuración inicial. ¡Sólo preocuparos de aprender!
Ofrecemos también la posibilidad de realizar formaciones en base a ‘Casos de Uso’
Se complementa la formación tradicional de un temario/horas/profesor con la realización de casos prácticos en las semanas posteriores al curso en base a datos reales de la propia organización, de forma que se puedan ir poniendo en producción proyectos iniciales con nuestro soporte, apoyo al desarrollo y revisión con los alumnos y equipos, etc…
En los 10 últimos años, ¡hemos formado a más de 250 organizaciones y 3.000 alumnos!
Ah, y regalamos nuestras famosas camisetas de Data Ninjas a todos los asistentes. No te quedes si las tuyas





Curso de Integración de fuentes externas y Web Scraping
Curso de Integración de fuentes externas y Web Scraping
Goal
En los últimos años, estamos presenciando una "revolución de datos" y un número significativo de organizaciones están invirtiendo dinero, innovación y esfuerzos para desbloquear su enorme potencial. Muchas organizaciones han comenzado a delinear una vía de transformación mediante el desarrollo de sus capacidades analíticas, aprovechando el diluvio de datos para transformar los números sin procesar, en información procesable para permitir una toma de decisiones más rápida y precisa.
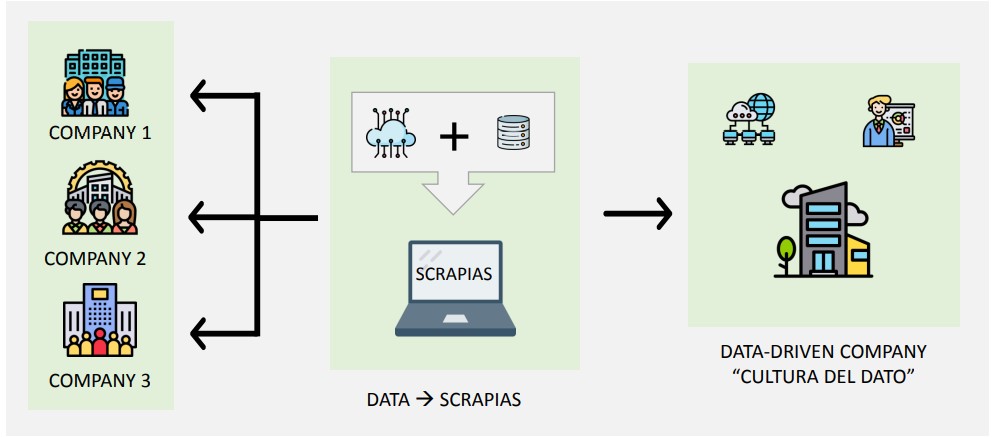
SCRAPIAS aparece como solución analítica para hacer frente a la cantidad ingente de datos que existen hoy en el mundo. Pretendemos ofrecer una solución a aquellas empresas que quieran unirse a la revolución de los datos que estamos sufriendo, y automatizar su proceso de extracción de datos para transformarlos en conocimiento.
Qué es el web scraping?
El web scraping es una técnica para extraer información de sitios web. Nos permite obtener datos no estructurados y convertirlos a un formato estructurado y utilizable, por ejemplo, CSV, tabla en una base de datos etc. También nos permite archivar datos o seguir los cambios de datos online.
Ejemplos de web scraping:
- Obtención de datos de contacto para campañas de marketing
- Monitorización de precios
- Creación de datasets para proyectos de machine learning
Datos de un sitio web
Hay muchas maneras de representar la información en una página web. Por lo cual el web scraping es diferente en cada una de ella.
Ejemplos
Aprenda a extraer datos desde una página web hacia tu aplicación Analítica.
Target audiences
Este curso está direccionado a profesionales o estudiantes de TI.
Competencias adquiridas tras la realización del curso:
- Capacidad de extracción de datos automatizada de diferentes fuentes abiertas, tanto estructuradas como no estructuradas (imagen, sonido, etc.)
- Incorporación de nuevas tecnologías para la realización de Web Scraping.
- Posibilidad de incorporación de datos procedentes de fuentes de dispositivos IoT (Internet of Things)
- Capacidad analítica, tanto descriptiva como predictiva, basada en los algoritmos más avanzados de Machine Learning e Inteligencia Artificial.
- Plataforma basada en tecnologías Open Source.
Requisitos: manejo de HTML y lenguajes de scripting (JavaScript, Python u otras).
Observations
Características de SCRAPIAS
- Extracción de diferentes fuentes abiertas (entre ellas fuentes de tipo Web Scraping, API's, etc.)
- Integración de fuentes de dispositivos IoT (Internet of Things), para la medición de temperaturas atmosféricas, telemetría, webs con información estadística, webs con información no estructurada (imagen sonido vídeo etc.), reconocimiento visual, etc.
- Exploración analítica mediante la aplicación de algoritmos de Machine Learning e Inteligencia Artificial.
- Basado en tecnologías Open Source.
- Generación automática de modelos y algoritmos que pueden ser usados en numerosas industrias y sectores.
Syllabus
- Qué es el web scraping?
- Datos de un sitio web
- Estructura
- Selectores HTML/ XPath
- Selectores XML
- BeautifulSoup
- Introducción y manejo de excepciones
- Tipos de objetos en BeautifulSoup
- Funciones find y find_all
- Recorrido de Árboles
- Expresiones Regulares
- Expresiones Lambda
- Selenium
- Instalar y configurar Chromedriver
- Selectores
- Espera de elementos HTML
- Ejecución de JavaScript
- Funciones del WebDriver
- Navegación
- Acciones
- Ejercicios (DGT, Portales públicos de Ayuda e incentivos)
- APIs con Requests
- Peticiones GET, POST, PUT, DELETE
- Autorización y cabecera
- Parseo de JSON
- API de Twitter y consumo servicios Open Data
- JSON
- Serializar JSON
- Deserializar JSON
- Deserialización de estructuras complejas
- Introducción a librerías jsonpickle y json
- Conversión entre objetos Python y JSON (diccionarios, listas, tuplas,)
- XML
- Introducción a XML etree
- Parseo de ficheros XML
- Funciones de lectura ( find, findall, findtext,iter)
6. Creación de Caso de Uso Práctico accediendo a fuentes externas
- SAP
- Salesforce
- Other ERPs, CRMs
- 3rd apps
- APIs
- Web Scraping
- Google Analytics
- Open Data
- IoT Data
- Conectores
Contacto
Ajustamos cada curso a sus necesidades.
Nuestra oficina en Madrid
- Avenida de Brasil 17. Planta 16
- 28046 Madrid
- info@stratebi.com
- Tlfno: +34 91.788.34.10
- Fax:+34 91.788.57.01