


Machine Learning
Machine Learning name is derived from the study of systems that can learn from the data. It is the ability of a system to generalize on the basis of experience. This is used to answer questions relating to previously collected data and data that have not been encountered before.
It is applied in many knowledge areas, such as statistics, pattern recognition, artificial intelligence, data mining, etc. By applying different types of algorithms these systems are capable of extracting knowledge automated: sorting, grouping, regression to generate predictions. It has a large number of possible applications that solve really complex problems: recommendation systems predict demand for a product, predict the price of a house, etc.
Large corporations employ 'Machine Learning' in their systems: Google, Facebook, Linkedin, Netflix, Amazon.
> Portfolio Technical Features Forecasting Recommender Systems Sentiment Analysis

TECHNICAL FEATURES
In the Pentaho suite, Pentaho Data Integration (PDI) and Weka enable the integration with the latest technologies in this field.
Weka
It is the tool within the analytic Pentaho Suite for predictive analysis. It contains a set of algorithms for automatic learning for data mining tasks. These algorithms can be applied either directly to a data set or by calling its own Java code. Weka has a set of tools for data pre-processing, classification, regression, clustering, association rules, and visualization.
Lenguages Python y R
In Python we can use machine learning oriented as pandas, scikit-learn, Pylearn2 packages, ...
If we use 'R', there are several library, such as e1071, rpart, igraph, nnet, randomForest, caret, kernlab, gbm, earth, mboost, ...
Big Data
There are machine learning tools with Big Data: Apache Mahout, MLIB operating on Apache Spark.
Forecasting: Demand forecasting models Holt-Winters and ARIMA
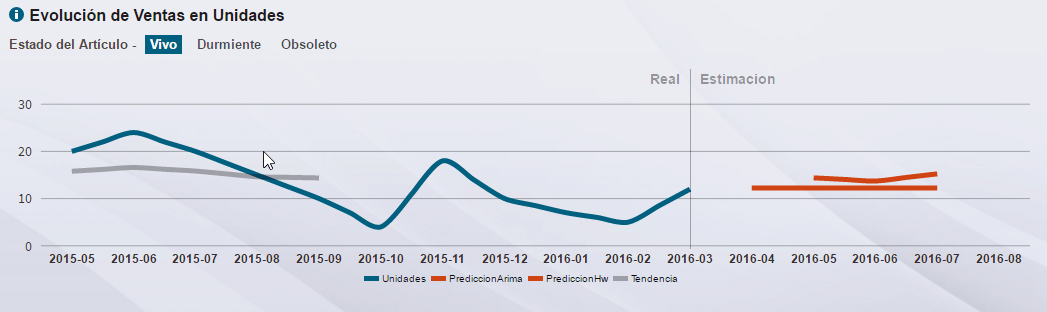
In Stratebi, there are specialists in the application and Holt-Winters ARIMA models for forecasting demand, adjusting the level of Stock and reducing Working Capital.
The integrated auto-regressive moving average or ARIMA model is a statistical model that uses variations in order to find patterns for a prediction for the future. This is a dynamic time series model, ie, future estimates are explained by past data and not by independent variables. The ARIMA model can be generalized even more to consider the effect of seasonality, in that case, we speak of a SARIMA model.
Holt-Winters (exponential smoothing method) is a way to forecast demand for a given period. Unlike many other techniques, the Holt-Winters model can easily adapt to changes and trends, as well as seasonal patterns. Compared to other techniques such as ARIMA, the time required to calculate the prognosis is considerably faster, it works better with shorter series.
Recommender Systems: Customizable suggestions for each type of user using collaborative filtering techniques.
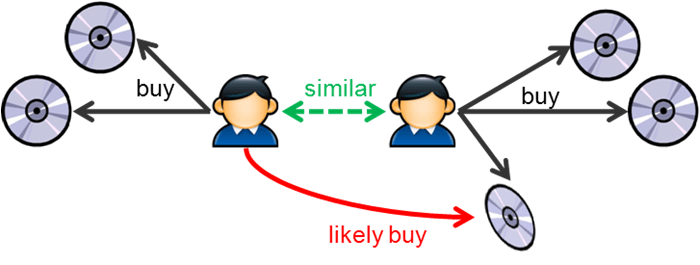
Nowadays, there are an infinite number of possibilities in almost every aspect of our lives, we have to make decisions from choosing a car to our house. Under these conditions, the possibility of recommending a choice is valuable, even if that option is customized for the person receiving the recommendation.
To perform this work they are used, among other, collaborative filtering techniques. Collaborative filtering logic focuses on user characteristics (previous purchases, preferences, qualifications has other products) and users who have taken similar decisions sought. Products that have been successful with similar users, surely will interest you the new user.
For istance:
- Amazon: Related Products
- Netflix: movie recommendation
- Google: autocomplete search
- Linkedin: Recommendation contacts
Sentiment Analysis: Improving the marketing of the company thanks to sentiment analysis
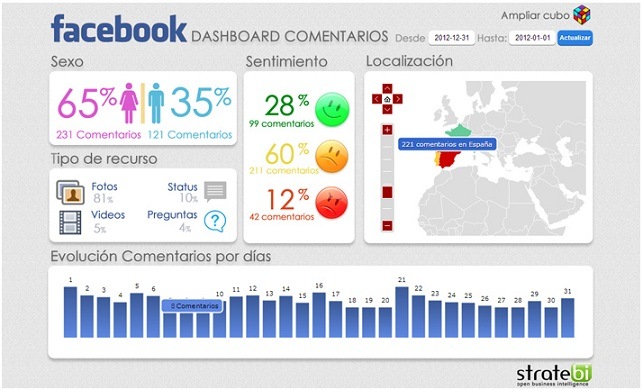
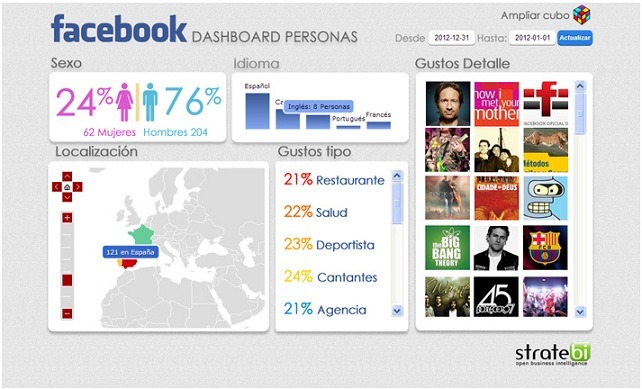
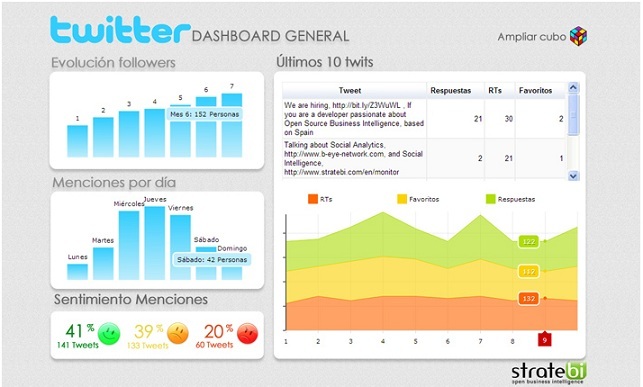
Thanks to sentiment analysis the impact of a brand or product within social networks can be measured. This technique is also known as opinion mining, classification of feelings or affective computing. It is used to extract and classify information subjective (opinions, ideas) in materials. That is, given a data source with a text format, which appear opinions or feelings about various entities or objects, to extract the opinions of them and classify them. You could say that is a computational treatment of the opinions, feelings and subjective phenomena of texts.
This technique uses natural language as it is used by the user. Handling computationally this language entails certain problems such as ambiguity of words as they depend heavily on context. The challenges it faces are: the extraction of the characteristics on which is reviewing and also the classification of these characteristics.
Our solution can generate benefits in the marketing department of a company, improving efficiency when analyzing the impact of marketing campaigns, analyzing whether positive or negative comments are obtained in all social networks (Twitter, Facebook, ...)